PyMotifs @CNRS
Task
The PyMotifs project is a Python-based initiative focused on developing a textual analysis methodology. This approach, known as the “motifs” method, was conceptualized by Dominique Legallois from Université Sorbonne Nouvelle Paris III and Antoine Silvestre de Sacy from the CNRS & Sorbonne-Nouvelle. Funded by a grant from the Humanistica association in 2021-2022 and a winner of the DARIAH Theme Call for 2023-2024, this project emphasizes the identification of lexico-grammatical patterns to enhance our understanding of textual data.
Challenges
Textual data presents unique challenges, including:
- Large datasets that are cumbersome to process and manage in memory.
- Very high dimensional feature space and sparse features can increase the complexity
My Contributions
My work on the PyMotifs project led to the development of the PyMotifs Python package, which is publicly available on GitHub. To address issues related to data size and memory management, I integrated sparse matrix techniques from SciPy and utilized the Gensim library for efficient feature computation. To expedite processing times, the package leverages multiprocessing capabilities provided by the Joblib library.
Key implementations within the PyMotifs package include:
- The development of a predictive analysis pipeline (accessible at Predict-doc) designed to classify pieces of text according to their document of origin. This tool is instrumental in identifying key lexico-grammatical motifs within documents.
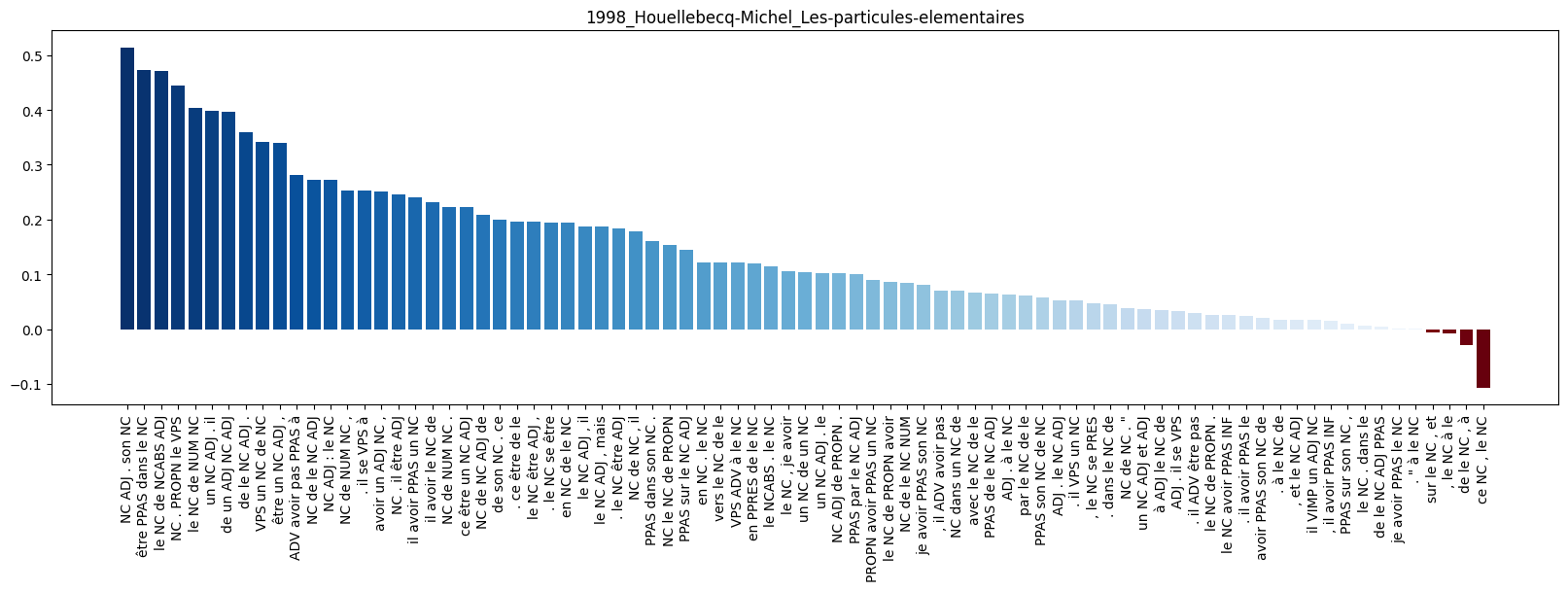 Selected features coefficients in the predictive model of a text belonging to “Les Particules Élémentaires” by Houellebecq.
Selected features coefficients in the predictive model of a text belonging to “Les Particules Élémentaires” by Houellebecq.
Note: The most important motif for “Les particules elementaires” by Houellebecq is “NC ADJ . son NC” with a coefficient of 0.51. It has a positive impact on the probability of a text to belong to “Les particules elementaires” by Houellebecq
The creation of another predictive pipeline (accessible at Predict-canon) that determines the canonical label of documents, enhancing document classification efforts.
class precision recall f1-score 0 0.72 0.66 0.69 1 0.70 0.76 0.73 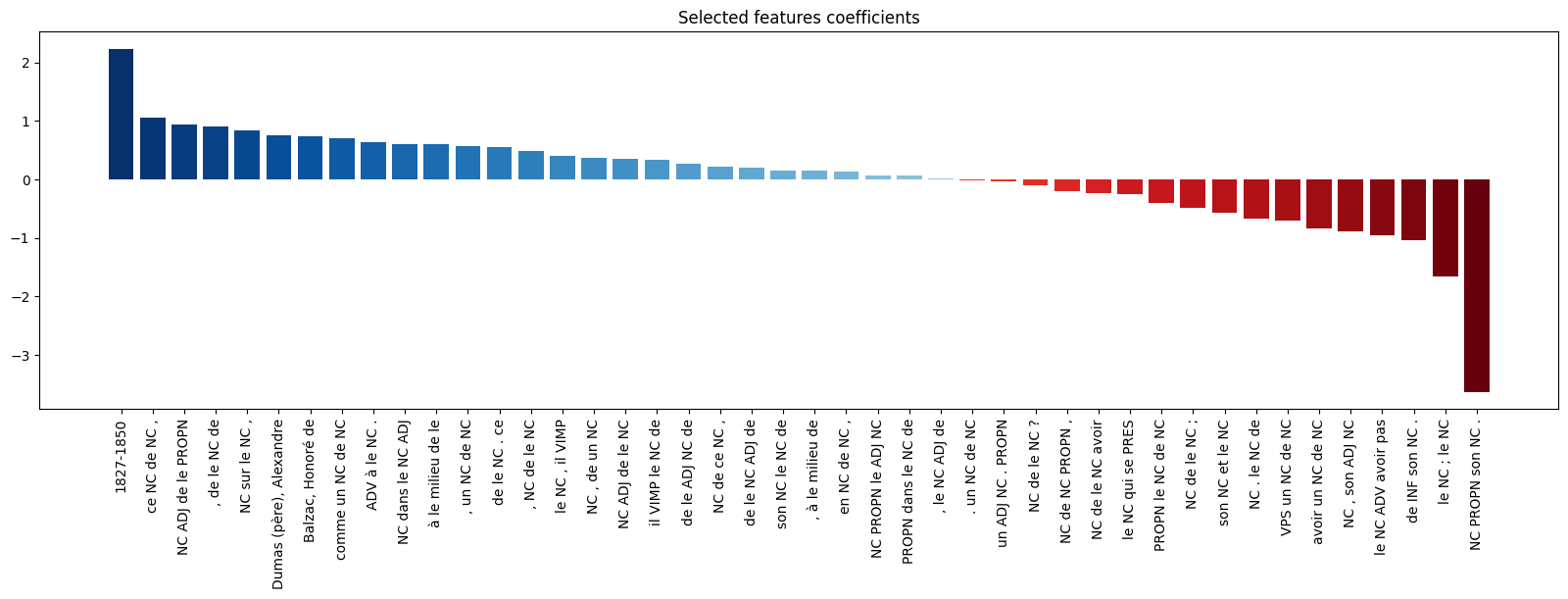 Selected features coefficients in the predictive model of canonical label of a document.
Selected features coefficients in the predictive model of canonical label of a document.
Note: We have selected 44 features: some motifs but also 2 authors (A. Dumas (père) and H. de Balzac), and 1 period (1827-1850). In our corpus, writings by A. Dumas and H. de Balzac are more likely to be regarded as canonical compared to those of other authors. On top, the period 1827-1850 has a strong positive impact on the target.The implementation of a clustering pipeline that groups documents based on shared motifs, facilitating deeper insights into textual patterns and themes.
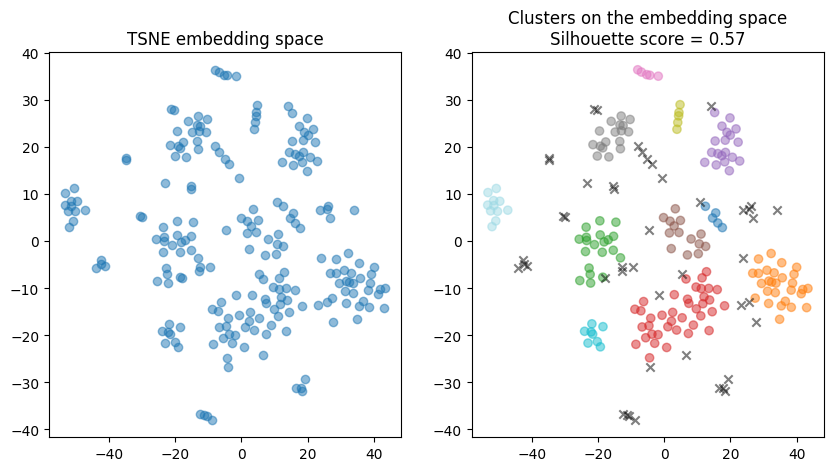 We find 11 clusters with DBSCAN in our corpus. The motif approach helps segment complex corpus in various groups that are probably defined by the author. The motif is a highly distinctive feature for the author.
We find 11 clusters with DBSCAN in our corpus. The motif approach helps segment complex corpus in various groups that are probably defined by the author. The motif is a highly distinctive feature for the author.